1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
| import tensorflow.compat.v1 as tf
import numpy as np
import matplotlib.pyplot as plt
tf.disable_eager_execution()
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.mnist.load_data()
train_y = tf.keras.utils.to_categorical(train_labels)
test_y = tf.keras.utils.to_categorical(test_labels)
train_data = train_data / 255
test_data = test_data / 255
print('train data', train_data.shape)
print('train label', train_labels.shape)
print('test data', test_data.shape)
print('test label', test_labels.shape)
plt.subplot(1, 4, 1)
plt.imshow(train_data[0], cmap='gray')
plt.subplot(1, 4, 2)
plt.imshow(train_data[1], cmap='gray')
plt.subplot(1, 4, 3)
plt.imshow(train_data[2], cmap='gray')
plt.subplot(1, 4, 4)
plt.imshow(train_data[3], cmap='gray')
plt.show()
LEARNING_RATE = 0.01
BATCH_SIZE = 100
EPOCH = 10
train_losses = []
test_losses = []
train_accuracies = []
test_accuracies = []
batch = len(train_labels)// BATCH_SIZE
batch_test = len(test_labels) // BATCH_SIZE
def get_weight(name, shape, gain=np.sqrt(2)):
total = np.prod(shape)
init_std = gain / np.sqrt(total)
init = tf.initializers.random_normal(0, init_std)
return tf.get_variable(name, shape=shape, initializer=init)
with tf.device('/cpu:0'):
x = tf.placeholder(tf.float32, [None, 28, 28])
x_data = tf.reshape(x, [-1, 28, 28, 1])
y_data = tf.placeholder(tf.float32, [None, 10])
lr = tf.placeholder(tf.float32)
bc1 = tf.Variable(tf.truncated_normal([32]))
bc2 = tf.Variable(tf.truncated_normal([64]))
b_fc = tf.Variable(tf.truncated_normal([512]))
b1 = tf.Variable(tf.truncated_normal([10]))
wc1 = get_weight('wc1', [3, 3, 1, 32])
wc2 = get_weight('wc2', [3, 3, 32, 64])
w_fc = get_weight('w_fc', [1600, 512])
w1 = get_weight('w1', [512, 10])
with tf.device('/cpu:0'):
out1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x_data, wc1, strides=[1, 1, 1, 1], padding='VALID'), bc1))
out2 = tf.nn.max_pool(out1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
out3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(out2, wc2, strides=[1, 1, 1, 1], padding='VALID'), bc2))
out4 = tf.nn.max_pool(out3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
out5 = tf.reshape(out4, shape=[BATCH_SIZE, -1])
out6 = tf.nn.relu(tf.matmul(out5, w_fc)+b_fc)
out7 = tf.nn.dropout(out6, keep_prob=0.8)
y_pred = tf.matmul(out7, w1)+b1
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_data, logits=y_pred))
optimizer = tf.train.AdagradOptimizer(learning_rate=lr).minimize(loss)
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y_pred, 1), tf.argmax(y_data, 1)), "float"))
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(EPOCH):
test_loss = 0
train_loss = 0
test_acc = 0
train_acc = 0
for now_batch in range(batch):
X = train_data[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
Y = train_y[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
sess.run(optimizer, feed_dict={x: X, y_data: Y, lr:LEARNING_RATE })
for now_batch in range(batch):
X = train_data[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
Y = train_y[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
loss_, acc = sess.run([loss, accuracy], feed_dict={x: X, y_data: Y})
train_loss += loss_
train_acc += acc
train_loss /= batch
train_acc /= batch
for now_batch in range(batch_test):
X = test_data[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
Y = test_y[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
loss_, acc = sess.run([loss, accuracy], feed_dict={x: X, y_data: Y})
test_loss += loss_
test_acc += acc
test_loss /= batch_test
test_acc /= batch_test
print('now epoch: {}, loss: {}, acc:{}'.format(epoch, test_loss, test_acc))
train_losses.append(train_loss)
test_losses.append(test_loss)
train_accuracies.append(train_acc)
test_accuracies.append(test_acc)
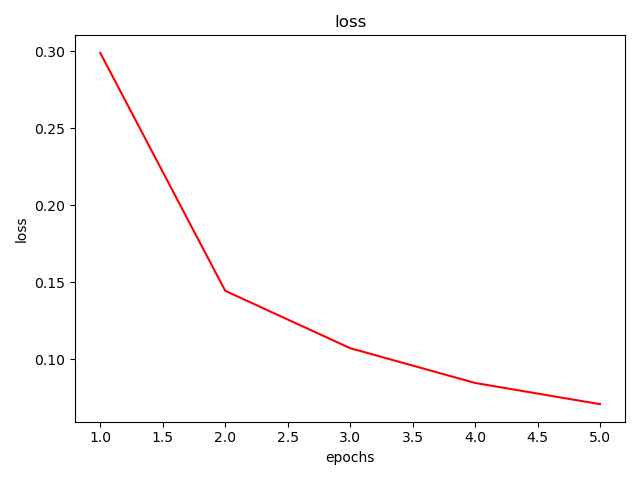
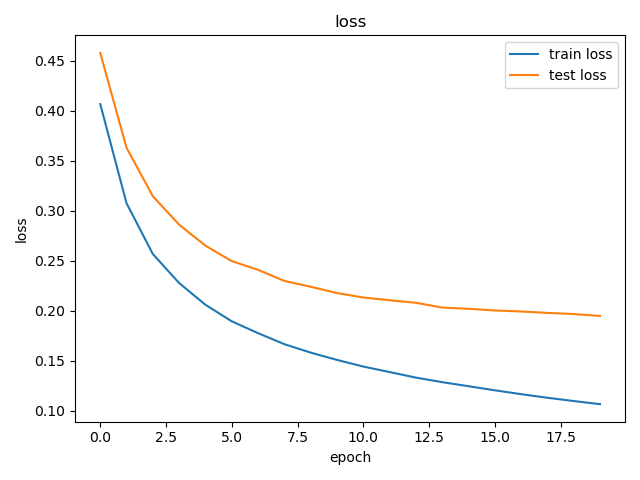
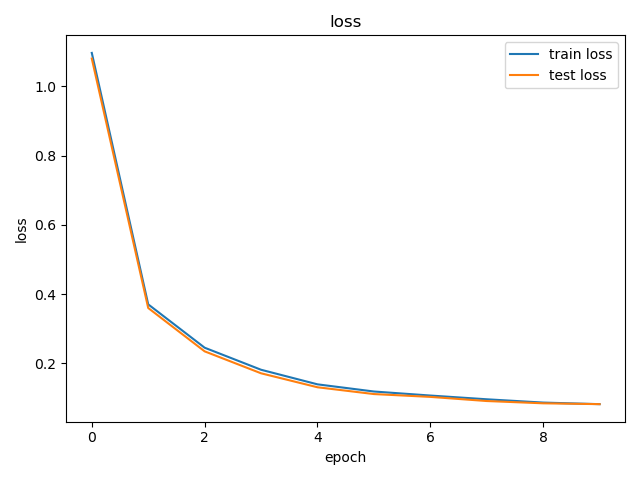
plt.title('loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.plot(train_losses)
plt.plot(test_losses)
plt.legend(['train loss', 'test loss'])
plt.show()
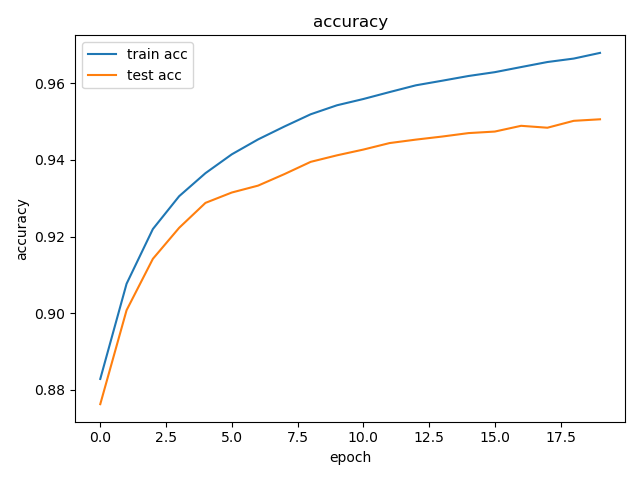
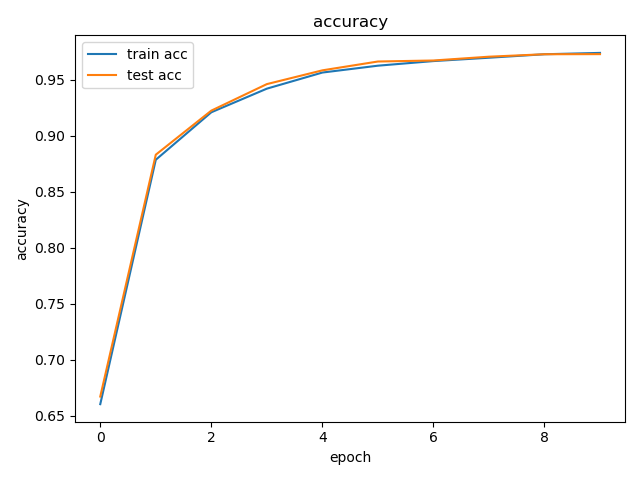
plt.title('accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.plot(train_accuracies)
plt.plot(test_accuracies)
plt.legend(['train acc', 'test acc'])
plt.show()
(train_data, train_labels), (test_data, test_labels) = tf.keras.datasets.mnist.load_data()
train_y = tf.keras.utils.to_categorical(train_labels)
test_y = tf.keras.utils.to_categorical(test_labels)
train_data = train_data / 255
test_data = test_data / 255
BATCH_SIZE = 100
LEARNING_RATE = 0.01
EPOCH = 5
train_losses = []
test_losses = []
train_accuracies = []
test_accuracies = []
batch = len(train_labels)// BATCH_SIZE
batch_test = len(test_labels) // BATCH_SIZE
def get_weight(name, shape, gain=np.sqrt(2)):
total = np.prod(shape)
init_std = gain / np.sqrt(total)
init = tf.initializers.random_normal(0, init_std)
return tf.get_variable(name, shape=shape, initializer=init)
with tf.device('/cpu:0'):
x = tf.placeholder(tf.float32, [None, 28, 28])
x_data = tf.reshape(x, [-1, 28, 28, 1])
y_data = tf.placeholder(tf.float32, [None, 10])
lr = tf.placeholder(tf.float32)
bc1 = tf.Variable(tf.truncated_normal([32]))
bc2 = tf.Variable(tf.truncated_normal([64]))
b_fc = tf.Variable(tf.truncated_normal([512]))
b1 = tf.Variable(tf.truncated_normal([10]))
wc1 = get_weight('wc1', [3, 3, 1, 32])
wc2 = get_weight('wc2', [3, 3, 32, 64])
w_fc = get_weight('w_fc', [1600, 512])
w1 = get_weight('w1', [512, 10])
with tf.device('/cpu:0'):
out1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x_data, wc1, strides=[1, 1, 1, 1], padding='VALID'), bc1))
out2 = tf.nn.max_pool(out1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
out3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(out2, wc2, strides=[1, 1, 1, 1], padding='VALID'), bc2))
out4 = tf.nn.max_pool(out3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
out5 = tf.reshape(out4, shape=[BATCH_SIZE, -1])
out6 = tf.nn.relu(tf.matmul(out5, w_fc)+b_fc)
out7 = tf.nn.dropout(out6, keep_prob=0.8)
y_pred = tf.matmul(out7, w1)+b1
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_data, logits=y_pred))
optimizer = tf.train.AdagradOptimizer(learning_rate=lr).minimize(loss)
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.argmax(y_pred, 1), tf.argmax(y_data, 1)), "float"))
init = tf.global_variables_initializer()
lr_his = []
lr_acc = []
for i in range(1,11):
LEARNING_RATE = 0.005*i
with tf.Session() as sess:
sess.run(init)
for epoch in range(EPOCH):
test_acc = 0
for now_batch in range(batch):
X = train_data[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
Y = train_y[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
sess.run(optimizer, feed_dict={x: X, y_data: Y, lr:LEARNING_RATE})
for now_batch in range(batch_test):
X = test_data[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
Y = test_y[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
loss_, acc = sess.run([loss, accuracy], feed_dict={x: X, y_data: Y})
test_acc += acc
test_acc /= batch_test
test_accuracies.append(test_acc)
lr_acc.append(test_accuracies[-1])
lr_his.append(LEARNING_RATE)
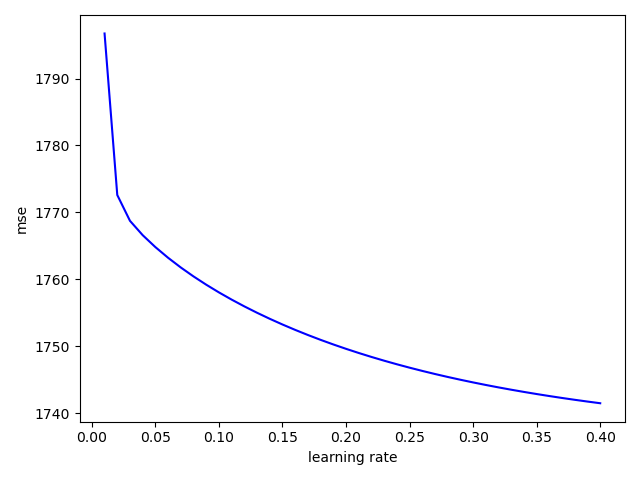
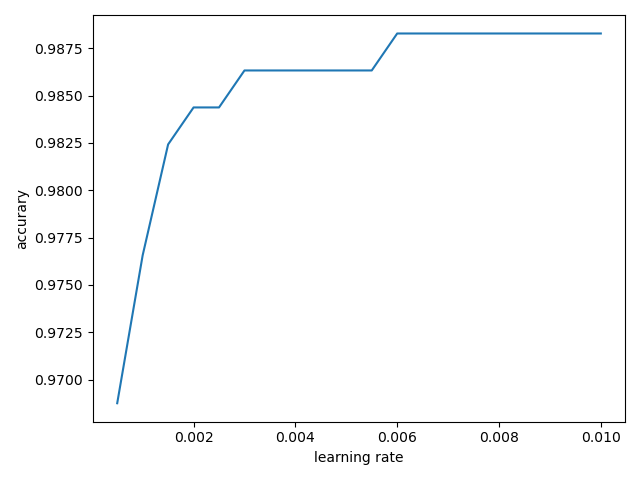
plt.title('accuracy')
plt.xlabel('leraning rate')
plt.ylabel('accuracy')
plt.plot(lr_his,lr_acc)
plt.show()
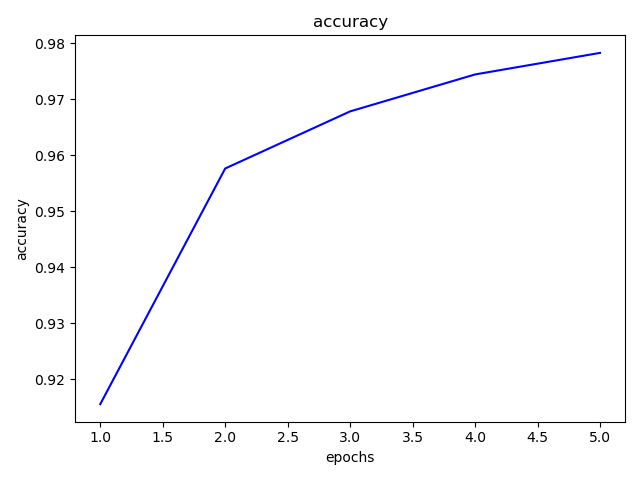
ep_acc = []
ep_his = []
for i in range(1,11):
EPOCH = i
with tf.Session() as sess:
sess.run(init)
for epoch in range(EPOCH):
test_acc = 0
for now_batch in range(batch):
X = train_data[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE].reshape(BATCH_SIZE, -1)
Y = train_y[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
sess.run(optimizer, feed_dict={x_data: X, y_data: Y, lr: LEARNING_RATE})
for now_batch in range(batch_test):
X = test_data[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE].reshape(BATCH_SIZE, -1)
Y = test_y[now_batch * BATCH_SIZE: (now_batch + 1) * BATCH_SIZE]
loss_, acc = sess.run([loss, accuracy], feed_dict={x_data: X, y_data: Y})
test_acc += acc
test_acc /= batch_test
test_accuracies.append(test_acc)
ep_acc.append(test_accuracies[-1])
ep_his.append(EPOCH)
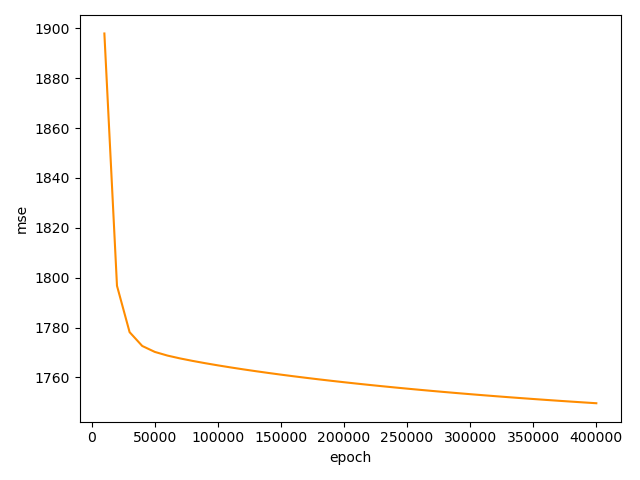
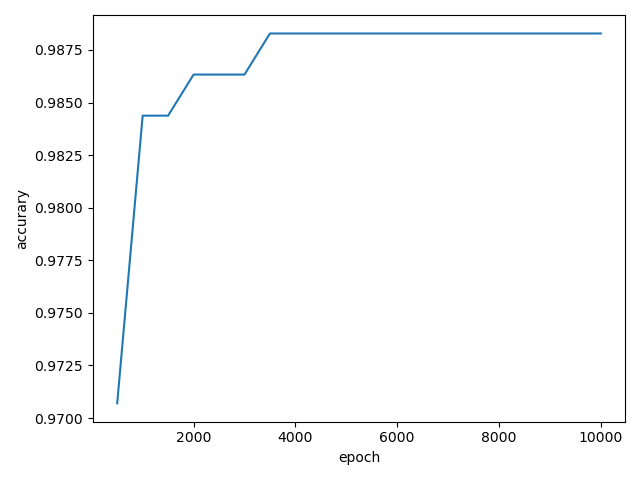
plt.title('accuracy')
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.plot(ep_his, ep_acc)
plt.show()
|
 微信
微信 支付宝
支付宝
