Python学习笔记
1. Python简介
1.1 Python 定义
是一个免费、开源、跨平台、动态、面向对象的编程语言。
1.2 Python程序的执行方式
(1)交互式
在命令行输入指令,回车即可得到结果。
(1) 打开终端
(2) 进入交互式:python3
(3) 编写代码:print(“hello world”)
(4) 离开交互式:exit()
(2)文件式
将指令编写到.py文件,可以重复运行程序。
(1) 编写文件
(2) 打开终端
(3) 进入程序所在目录:cd 目录
(4) 执行程序: python3 文件名
1.3 执行过程
计算机只能识别机器码(1010),不能识别源代码(python)。由源代码转变成机器码的过程分成两类:编译和解释。
(1)编译
在程序运行之前,通过编译器将源代码变成机器码,例如:C语言。
- 优点:运行速度快
- 缺点:开发效率低,不能跨平台。
(2)解释
在程序运行之时,通过解释器对程序逐行翻译,然后执行,例如Javascript。
- 优点:开发效率高,可以跨平台;
- 缺点:运行速度慢。
(3)Python是解释型语言
Python是解释型语言,但为了提高运行速度,使用了一种编译的方法。编译之后得到pyc文件,存储了字节码(特定于Python的表现形式,不是机器码)。
源代码 – 编译 –> 字节码 – 解释 –> 机器码
1.4 解释器类型
(1) CPython(C语言开发)
(2) Jython (java开发)
(3) IronPython (.net开发)
2. 数据基本运算
2.1 基础知识
(1) pycharm常用快捷键
移动到本行开头:home键
移动到本行末尾:end键盘
注释代码:ctrl + /
- 复制行:ctrl +d
- 删除行:shift + delete
- 选择列:shift + alt +鼠标左键
- 移动行:ctrl + shift + 上下箭头
- 代码格式化: ctrl+alt+l
- 查看函数参数:ctrl+P
- 重构成员:shift+F6
(2)注释
给人看的,通常是对代码的描述信息。
- 单行注释:以#号开头。
- 多行注释:三引号开头,三引号结尾。
2.2 数据
整形int
浮点型float
字符串str
布尔bool
2.3 运算
(1) 类型转换
- 转换为整形: int(数据)
- 转换为浮点型:float(数据)
- 转换为字符串:str(数据)
- 转换为布尔:bool(数据)
(2)运算符
(1)算术运算符
- + 加法
- - 减法
- * 乘法
- / 除法:结果为浮点数
- // 整除:除的结果去掉小数部分
- % 求余
- ** 幂运算
(2) 增强运算符
- y += x 相当于 y = y + x
- y -= x 相当于 y = y - x
- y *= x 相当于 y = y * x
- y /= x 相当于 y = y / x
- y //= x 相当于 y = y // x
- y %= x 相当于 y = y % x
- y **= x 相当于 y = y ** x
(3) 比较运算符
- < 小于
- <= 小于等于
> 大于
>= 大于等于
- == 等于
- != 不等于
(4) 逻辑运算符
- 与and
- 或or
- 非 not
(5)身份运算符
语法:
x is y
x is not y
作用:
is 用于判断两个对象是否是同一个对象,是时返回True,否则返回False。
(6)优先级
高到低:
算数运算符
比较运算符
增强运算符
身份运算符
逻辑运算符
3. 语句
3.1 条件语句
(1)if elif 语句
- 作用:
让程序根据条件选择性的执行语句。
- 语法:
1 | if 条件1: |
(2)真值表达式
1 | if 100: |
(3)条件表达式
- 语法:变量 = 结果1 if 条件 else 结果2
1 | value = 1 if input("请输入性别:") == "男" else 0 |
- 作用:根据条件(True/False) 来决定返回结果1还是结果2。
3.2 循环语句
(1)while语句
(2)for 语句
- 作用:用来遍历可迭代对象的数据元素。可迭代对象是指能依次获取数据元素的对象,例如:容器类型。
- 语法:
1 | for 变量列表 in 可迭代对象: |
(3)range 函数
- 作用:
用来创建一个生成一系列整数的可迭代对象(也叫整数序列生成器)。
- 语法:
range(开始点,结束点,间隔)
说明:
函数返回的可迭代对象可以用for取出其中的元素
返回的数字不包含结束点
开始点默认为0
间隔默认值为1
1 | # 写法1:range(开始,结束,间隔) |
3.3 跳转语句
(1)break 语句
跳出循环体,后面的代码不再执行。
(2)continue 语句
跳过本次,继续下次循环。
4. Python基础容器
Python基础容器5. 函数 function
5.1 定义
- 用于封装一个特定的功能,表示一个功能或者行为。
- 函数是可以重复执行的语句块, 可以重复调用。
- 提高代码的可重用性和可维护性(代码层次结构更清晰)。
5.2 基础语法
(1)定义函数
语法:
def 函数名(形式参数):
函数体说明:
def 关键字:全称是define,意为”定义”。
函数名:对函数体中语句的描述,规则与变量名相同。
形式参数:函数定义者要求调用者提供的信息。
函数体:完成该功能的语句。
- 函数的第一行语句建议使用文档字符串描述函数的功能与参数。
(2)调用函数
- 语法:函数名(实际参数)
- 说明:根据形参传递内容。
(3)返回值
定义:
函数定义者告诉调用者的结果。
语法:
return 数据
说明:
return后没有语句,相当于返回 None。
函数体没有return,相当于返回None。
5.3 可变/不可变类型
(1) 不可变类型参数:
- 数值型(整数,浮点数)
- 布尔值bool
- None 空值
- 字符串str
- 元组tuple
(2) 可变类型参数:
- 列表 list
- 字典 dict
- 集合 set
(3) 传参说明:
- 不可变类型的数据传参时,函数内部不会改变原数据的值。
- 可变类型的数据传参时,函数内部可以改变原数据。
5.4 函数参数
(1)实参传递方式
①位置传参
定义:实参与形参的位置依次对应。
1 | def fun01(p1, p2, p3): |
②序列传参
定义:实参用*将序列拆解后与形参的位置依次对应。
1 | def func01(p1, p2, p3): |
③关键字传参
定义:实参根据形参的名字进行对应。
1 | def fun01(p1, p2, p3): |
④字典关键字传参
定义:实参用**将字典拆解后与形参的名字进行对应。
作用:配合形参的缺省参数,可以使调用者随意传参。
1 | def func01(p1, p2, p3): |
(2)形参定义方式
①缺省形参
语法:
def 函数名(形参名1=默认实参1, 形参名2=默认实参2, …):
函数体
说明:
缺省参数必须自右至左依次存在,如果一个参数有缺省参数,则其右侧的所有参数都必须有缺省参数。
1 | def func01(p1=0, p2="", p3=100): |
②位置形参
语法:
def 函数名(形参名1, 形参名2, …):
函数体
③命名关键字形参
语法:
def 函数名(*args, 命名关键字形参1, 命名关键字形参2, …):
函数体def 函数名(*, 命名关键字形参1, 命名关键字形参2, …):
函数体
作用:
强制实参使用关键字传参
1 | # 命名关键字形参: |
④星号元组形参
语法:
def 函数名(*元组形参名):
函数体
作用:
可以将多个位置实参合并为一个元组
说明:
一般命名为’args,形参列表中最多只能有一个
1 | # 位置实参数量可以无限 |
⑤双星号字典形参
语法:
def 函数名(**字典形参名):
函数体
作用:
可以将多个关键字实参合并为一个字典
说明:
一般命名为‘kwargs
形参列表中最多只能有一个
1 | # 关键字实参数量无限 |
⑥参数自左至右的顺序
位置形参 –> 星号元组形参 –> 命名关键字形参 –> 双星号字典形参
练习:说出程序执行结果.
1 | def func01(list_target): |
6. 作用域
6.1 定义
变量起作用的范围。
6.2 分类
(1) Local 局部作用域:函数内部。
(2) Enclosing 外部嵌套作用域 :函数嵌套。
(3) Global 全局作用域:模块(.py文件)内部。
(4) Builtin 内置模块作用域:builtins.py文件。
6.3 变量名的查找规则
(1) 由内到外:L -> E -> G -> B
(2) 在访问变量时,先查找本地变量,然后是包裹此函数外部的函数内部的变量,之后是全局变量,最后是内置变量。
6.4 局部变量
(1) 定义在函数内部的变量(形参也是局部变量)
(2) 只能在函数内部使用
(3) 调用函数时才被创建,函数结束后自动销毁
6.5 全局变量
(1) 定义在函数外部,模块内部的变量。
(2) 在整个模块(py文件)范围内访问(但函数内不能将其直接赋值)。
6.6 global 语句
(1) 作用:
在函数内部修改或定义全局变量(全局声明)。
(2) 语法:
global 变量1, 变量2, …
(3) 说明
在函数内直接为全局变量赋值,视为创建新的局部变量。
不能先声明局部的变量,再用global声明为全局变量。
6.7 nonlocal 语句
(1) 作用:
在内层函数修改外层嵌套函数内的变量
(2) 语法
nonlocal 变量名1,变量名2, …
(3) 说明
在被嵌套的内函数中进行使用
1 | # 2. 全局作用域:文件内部 |
练习:画出下列代码内存图
1 | data01 = 10 |
7. 面向对象简介
7.1 面向过程
(1) 定义:分析出解决问题的步骤,然后逐步实现。
例如:婚礼筹办
– 请柬(选照片、措词、制作)
– 宴席(场地、找厨师、准备桌椅餐具、计划菜品、购买食材)
– 仪式(定婚礼仪式流程、请主持人)
(2) 公式:程序 = 算法 + 数据结构
(3) 优点:所有环节、细节自己掌控。
(4) 缺点:考虑所有细节,工作量大。
7.2 面向对象
(1) 定义:找出解决问题的人,然后分配职责。
例如:婚礼筹办
– 发请柬:找摄影公司(拍照片、制作请柬)
– 宴席:找酒店(告诉对方标准、数量、挑选菜品)
– 婚礼仪式:找婚庆公司(对方提供司仪、制定流程、提供设备、帮助执行)
(2) 公式:程序 = 对象 + 交互
(3) 优点
a. 思想层面:
– 可模拟现实情景,更接近于人类思维。
– 有利于梳理归纳、分析解决问题。
b. 技术层面:
– 高复用:对重复的代码进行封装,提高开发效率。
– 高扩展:增加新的功能,不修改以前的代码。
– 高维护:代码可读性好,逻辑清晰,结构规整。
(4) 缺点:学习曲线陡峭。
8. 类和对象
8.1 语法
(1)定义类
- 代码
1 | class 类名: |
- 说明
- 类名所有单词首字母大写.
- init 也叫构造函数,创建对象时被调用,也可以省略。
- self 变量 绑定的是被创建的对象,名称可以随意。
(2)实例化对象
- 代码
1 | 变量 = 类名(参数) |
- 说明
- 变量存储的是实例化后的对象地址
- 类名后面的参数按照构造函数的形参传递
2.2 实例成员
(1) 实例变量
定义
1
对象.变量名
调用
1
对象.变量名
说明
首次通过对象赋值为创建,再次赋值为修改.
通常在构造函数(__init_)中创建
每个对象存储一份,通过对象地址访问
- 作用:描述某个对象的数据。
- _dict_:对象的属性,用于存储自身实例变量的字典。
(2)实例方法
- 定义
1 | def 方法名称(self, 参数): |
- 调用:
1 | 对象.方法名称(参数) |
说明
- 至少有一个形参,第一个参数绑定调用这个方法的对象,一般命名为self。
- 无论创建多少对象,方法只有一份,并且被所有对象共享。
作用:表示对象行为。
2.3 类成员
(1)类变量
- 定义:在类中,方法外。
1 | class 类名: |
- 调用:
1 | 类名.变量名 |
特点:
随类的加载而加载
存在优先于对象
只有一份,被所有对象共享。
作用:描述所有对象的共有数据。
(2) 类方法
- 定义:
1 |
|
- 调用:
1 | 类名.方法名(参数) |
说明
- 至少有一个形参,第一个形参用于绑定类,一般命名为’cls’
- 使用@classmethod修饰的目的是调用类方法时可以隐式传递类。
类方法中不能访问实例成员,实例方法中可以访问类成员。
- 作用:操作类变量。
2.4 静态方法
- 定义:
1 |
|
- 调用:
1 | 类名.方法名称(参数) |
- 说明
- 使用@ staticmethod修饰的目的是该方法不需要隐式传参数。
- 静态方法不能访问实例成员和类成员
- 作用:定义常用的工具函数。
9. 面向对象三大特征
9.1 封装
(1)数据角度
- 定义:将一些基本数据类型复合成一个自定义类型。
优势:
将数据(变量)与对数据的操作(方法)相关联。
代码可读性更高(类是对象的模板)。
(2)行为角度
定义:
向类外提供必要的功能,隐藏实现的细节。
优势:
简化编程,使用者不必了解具体的实现细节,只需要调用对外提供的功能。
(3)设计角度
- 分而治之
- 将一个大的需求分解为许多类,每个类处理一个独立的功能
- 拆分好处:便于分工,便于复用,可扩展性强
- 变则疏之
- 变化的地方独立封装,避免影响其他类
- 高内聚
- 类中各个方法都在完成一项任务(单一职责的类)
- 低耦合
- 类与类的关联性与依赖度较低(每个类独立),让一个类改变尽量不影响其他类。
(4)私有成员:
- 作用:无需向类外提供的成员,可以通过私有化进行屏蔽。
- 做法:命名使用双下划线开头。
- 本质:障眼法,实际也可以访问。
私有成员的名称被修改为:_类名__成员名,可以通过___dict__属性查看。
– 演示
1 | class MyClass: |
(5)属性@property
- 作用:保护实例变量(读取、只读、只写)
- 定义:
1 |
|
- 调用:
1 | 对象.属性名 = 数据 |
- 三种形式:
1 | # 1. 读写属性 |
1 | # 2. 只读属性 |
1 | # 3. 只写属性 |
9.2 继承
(1)继承方法
- 语法:
1 | class 父类: |
说明:
子类直接拥有父类的方法.
演示:
(2)内置函数
isinstance(对象, 类型)
返回指定对象是否是某个类的对象。
issubclass(类型,类型)
返回指定类型是否属于某个类型。
(3)继承数据
- 语法
1 | class 子类(父类): |
- 说明
子类如果没有构造函数,将自动执行父类的,但如果有构造函数将覆盖父类的。此时必须通过super()函数调用父类的构造函数,以确保父类实例变量被正常创建。
- 演示
1 | class Person: |
(4) 练习:
创建父类:车(品牌,速度)
创建子类:电动车(电池容量,充电功率)
创建子类对象并画出内存图。
(4) 定义
- 概念: 重用现有类的功能,并在此基础上进行扩展。
- 说明:子类直接具有父类的成员(共性),还可以扩展新功能。
相关知识
父类(基类、超类)、子类(派生类)。
父类相对于子类更抽象,范围更宽泛;子类相对于父类更具体,范围更狭小。
单继承:父类只有一个(例如 Java,C#)。
多继承:父类有多个(例如C++,Python)。
Object类:任何类都直接或间接继承自 Object 类。
(5)多继承
- 定义:一个子类继承两个或两个以上的基类,父类中的属性和方法同时被子类继承下来。
同名方法解析顺序(MRO, Method Resolution Order):
类自身 –> 父类继承列表(由左至右)–> 再上层父类
A
/ \
/ \
B C
\ /
\ /
D
(3) 练习:写出下列代码在终端中执行效果
1 | class A: |
9.3 多态
(1)重写内置函数
- 定义:Python中,以双下划线开头、双下划线结尾的是系统定义的成员。我们可以在自定义类中进行重写,从而改变其行为。
- __str__ 函数:将对象转换为字符串(对人友好的)
1 | class Person: |
- 算数运算符重载
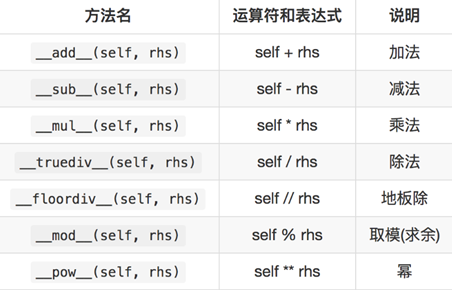
1 | class Vector2: |
- 复合运算符重载
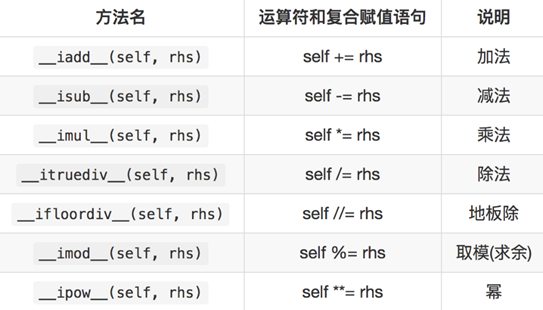
1 | class Vector2: |
- 比较运算重载
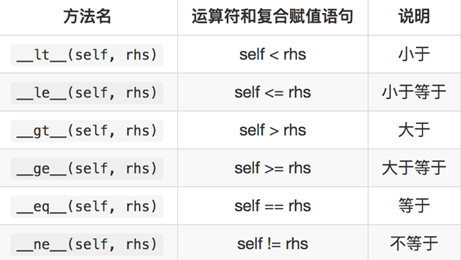
– 演示
1 | class Vector2: |
(2)重写自定义函数
- 子类实现了父类中相同的方法(方法名、参数),在调用该方法时,实际执行的是子类的方法。
- 快捷键:ctrl + O
- 作用
- 在继承的基础上,体现类型的个性(一个行为有不同的实现)。
- 增强程序灵活性。
10. 程序结构
10.1 模块 Module
(1)定义
包含一系列数据、函数、类的文件,通常以**.py**结尾。
(2)作用
让一些相关的数据,函数,类有逻辑的组织在一起,使逻辑结构更加清晰。有利于多人合作开发。
(3)导入
import
语法:
import 模块名
import 模块名 as 别名
作用:将模块整体导入到当前模块中
使用:
模块名.成员
别名.成员
from import
语法:
from 模块名 import 成员名
from 模块名 import 成员名 as 别名
from 模块名 import *
作用:将模块内的成员导入到当前模块作用域中
使用:直接使用成员名
(4)模块变量
- __doc__变量:文档字符串。
__name__变量:模块自身名字,可以判断是否为主模块。
当此模块作为主模块(第一个运行的模块)运行时,__name__绑定’__main__‘,不是主模块,而是被其它模块导入时,存储模块名。
(5) 加载过程
- 在模块导入时,模块的所有语句会执行。
- 如果一个模块已经导入,则再次导入时不会重新执行模块内的语句。
(6)分类
- 内置模块(builtins),在解析器的内部可以直接使用。
- 标准库模块,安装Python时已安装且可直接使用。
- 第三方模块(通常为开源),需要自己安装。
- 用户自己编写的模块(可以作为其他人的第三方模块)
10.2 包package
(1)定义
将模块以文件夹的形式进行分组管理。让一些相关的模块组织在一起,使逻辑结构更加清晰。
(2)__init.py的作用
_init_.py 在包被导入时会被执行
表示(标识)一个Python Package
对于自己写的模块,想要一键导入,单单这样写:
1 | from package import * |
是不够的,要在_init_.py中加入
1 | __all__ = [‘module1’,‘module2’,.] |
(3)导入
import
语法:
import 包
import 包 as 别名
作用:将包中__init__模块内整体导入到当前模块中
使用:包.成员
from import
语法:
from 包 import 成员
from 包 import 成员 as 别名
作用:将包中__init__模块内的成员导入到当前模块作用域中
使用:直接使用成员名
演示:
目录结构:
main.py
package01/
__init__.py
module01.py
1 | """ |
1 | """ |
1 | """ |
11. 异常处理
11.1 异常
(1)定义
运行时检测到的错误。
(2)现象
当异常发生时,程序不会再向下执行,而转到函数的调用语句。
(3)常见异常类型
- 名称异常(NameError):变量未定义。
类型异常(TypeError):不同类型数据进行运算。
索引异常(IndexError):超出索引范围。
属性异常(AttributeError):对象没有对应名称的属性。
键异常(KeyError):没有对应名称的键。
异常基类Exception。
11.2 处理
(1)语法:
1 | try: |
(2)作用
将程序由异常状态转为正常流程。
(3)说明
- as 子句是用于绑定错误对象的变量,可以省略
- except子句可以有一个或多个,用来捕获某种类型的错误。
- else子句最多只能有一个。
- finally子句最多只能有一个,如果没有except子句,必须存在。
- 如果异常没有被捕获到,会向上层(调用处)继续传递,直到程序终止运行。
11.3 raise 语句
(1) 作用
抛出一个错误,让程序进入异常状态。
(2)目的
在程序调用层数较深时,向主调函数传递错误信息要层层return比较麻烦,所以人为抛出异常,可以直接传递错误信息。
1 | class Wife: |
12. 迭代器iterator
每一次对过程的重复称为一次“迭代”,而每一次迭代得到的结果会作为下一次迭代的初始值。例如:循环获取容器中的元素。
12.1 可迭代对象iterabale
(1)定义
可迭代对象:具有__iter__函数的对象,可以返回迭代器对象。如字符串,列表等。
(2)语法
1 | # 创建: |
(3)原理
1 | 迭代器 = 可迭代对象.__iter__() |
(4)演示
1 | message = "我是花果山水帘洞孙悟空" |
12.2 迭代器对象iterator
(1)定义
可以被next()函数调用并返回下一个值的对象。
(2)语法
1 | class 迭代器类名: |
(3)说明
聚合对象通常是容器对象。
(4)作用
使用者只需通过一种方式,便可简洁明了的获取聚合对象中各个元素,而又无需了解其内部结构。
(5)演示:
1 | class StudentIterator: |
13. 生成器generator
- 定义:能够动态(循环一次计算一次返回一次)提供数据的可迭代对象。
- 作用:在循环过程中,按照某种算法推算数据,不必创建容器存储完整的结果,从而节省内存空间。数据量越大,优势越明显。以上作用也称之为延迟操作或惰性操作,通俗的讲就是在需要的时候才计算结果,而不是一次构建出所有结果。
13.1 生成器函数
(1)定义
含有yield语句的函数,返回值为生成器对象。
(2)语法
1 | # 创建: |
(3)说明
- 调用生成器函数将返回一个生成器对象,不执行函数体。
- yield翻译为”产生”或”生成”
(4)执行过程:
a. 调用生成器函数会自动创建迭代器对象。
b. 调用迭代器对象的__next__()方法时才执行生成器函数。
c. 每次执行到yield语句时返回数据,暂时离开。
d. 待下次调用__next__()方法时继续从离开处继续执行。
(5)原理
生成迭代器对象的大致规则如下
a. 将yield关键字以前的代码放在next方法中。
b. 将yield关键字后面的数据作为next方法的返回值。
(6) 演示:
1 | def my_range(stop): |
13.2 内置生成器
(1)枚举函数enumerate
- 语法:
1 | for 变量 in enumerate(可迭代对象): |
- 作用:遍历可迭代对象时,可以将索引与元素组合为一个元组。
- 演示:
1 | list01 = [43, 43, 54, 56, 76] |
(2)zip
- 语法:
1 | for item in zip(可迭代对象1, 可迭代对象2): |
- 作用:将多个可迭代对象中对应的元素组合成一个个元组,生成的元组个数由最小的可迭代对象决定。
- 演示:
1 | list_name = ["悟空", "八戒", "沙僧"] |
13.3 生成器表达式
- 定义:用推导式形式创建生成器对象。
- 语法:
1 | 变量 = (表达式 for 变量 in 可迭代对象 if 条件) |
14. 函数式编程
定义:用一系列函数解决问题。
- 函数可以赋值给变量,赋值后变量绑定函数。
- 允许将函数作为参数传入另一个函数。
- 允许函数返回一个函数。
高阶函数:将函数作为参数或返回值的函数。
14.1 函数作为参数
将核心逻辑传入方法体,使该方法的适用性更广,体现了面向对象的开闭原则。
1 | list01 = [342, 4, 54, 56, 6776] |
1 | # 参数:得到的是列表中的元素 |
(1)lambda 表达式
- 定义:是一种匿名方法
作用:
- 作为参数传递时语法简洁,优雅,代码可读性强。
- 随时创建和销毁,减少程序耦合度。
语法
1 | # 定义: |
- 说明:
- 形参没有可以不填
- 方法体只能有一条语句,且不支持赋值语句。
(5) 演示:
1 | from common.iterable_tools import IterableHelper |
(2)内置高阶函数
- map(函数,可迭代对象):使用可迭代对象中的每个元素调用函数,将返回值作为新可迭代对象元素;返回值为新可迭代对象。
- filter(函数,可迭代对象):根据条件筛选可迭代对象中的元素,返回值为新可迭代对象。
- sorted(可迭代对象,key = 函数, reverse = bool值):排序,返回值为排序结果。
- max(可迭代对象,key = 函数):根据函数获取可迭代对象的最大值。
- min(可迭代对象,key = 函数):根据函数获取可迭代对象的最小值。
- 演示:
1 | class Employee: |
14.2 函数作为返回值
逻辑连续,当内部函数被调用时,不脱离当前的逻辑。
(1)闭包
三要素:
- 必须有一个内嵌函数。
- 内嵌函数必须引用外部函数中变量。
- 外部函数返回值必须是内嵌函数。
语法
1 | # 定义: |
定义:是由函数及其相关的引用环境组合而成的实体。
优点:内部函数可以使用外部变量。
- 缺点:外部变量一直存在于内存中,不会在调用结束后释放,占用内存。
作用:实现python装饰器。
1
2
3
4
5
6
7
8
9
10
11# 装饰器
# 定义:
def 函数装饰器名称(func):
def 内部函数名(*args, **kwarg):
需要添加的新功能
return func
return 内部函数名
def 被装饰函数名():
原来的功能
(7) 演示:
1 | def give_gife_money(money): |
(2)函数装饰器decorator
- 定义:在不改变原函数的调用以及内部代码情况下,为其添加新功能的函数。
- 语法
1 | def 函数装饰器名称(func): |
- 本质:使用“@函数装饰器名称”修饰原函数,等同于创建与原函数名称相同的变量,关联内嵌函数;故调用原函数时执行内嵌函数。
原函数名称 = 函数装饰器名称(原函数名称)
1 | def func01(): |
装饰器链:
一个函数可以被多个装饰器修饰,执行顺序为从近到远。
15. 文件操作
15.1 文件与字节串
(1)文件
文件是保存在持久化存储设备(硬盘、U盘、光盘..)上的一段数据。从格式编码角度分为文本文件(打开后会自动解码为字符)、二进制文件(视频、音频等)。在Python里把文件视作一种类型的对象,类似之前学习过的其它类型。
(2)字节串(bytes)
在python3中引入了字节串的概念,与str不同,字节串以字节序列值表达数据,更方便用来处理二进程数据。因此在python3中字节串是常见的二进制数据展现方式。
- 普通的ascii编码字符串可以在前面加b转换为字节串,例如:b’hello’
- 字符串转换为字节串方法 :str.encode()
- 字节串转换为字符串方法 : bytes.decode()
15.2 文件读写
(1)打开文件
file_object = open(file_name, access_mode=’r’, buffering=-1)
功能:打开一个文件,返回一个文件对象。
参数:
file_name 文件名;
access_mode 打开文件的方式,如果不写默认为‘r’
文件模式 操作 r 以读方式打开,文件必须存在 w 以写方式打开,文件不存在则会创建,存在则清空原有内容 a 以追加模式打开 r+ 以读写模式打开,文件必须存在 w+ 以读写模式打开,不存在则会创建,存在则清空原有内容 a+ 以读写模式打开,追加模式 rb 以二进制读模式打开,同r wb 以二进制写模式打开,同w ab 以二进制追加模式打开,同a rb+ 以二进制读写模式打开,同r+ wb+ 以二进制读写模式打开,同w+ ab+ 以二进制读写模式打开,同a+
- buffering 1表示有行缓冲,默认则表示使用系统默认提供的缓冲机制。
- 返回值:成功返回文件操作对象。
注意
- 加b的打开方式读写要求必须都是字节串
- 无论什么文件都可以使用二进制方式打开,但是二进制文件使用文本方式打开读写会出错
(2)读取文件
read([size])
- 功能: 来直接读取文件中字符。
- 参数: 如果没有给定size参数(默认值为-1)或者size值为负,文件将被读取直至末尾,给定size最多读取给定数目个字符(字节)。
- 返回值: 返回读取到的内容
- 注意:文件过大时候不建议直接读取到文件结尾,读到文件结尾会返回空字符串。
readline([size])
- 功能: 指定的用来读取文件中一行
- 参数: 如果没有给定size参数(默认值为-1)或者size值为负,表示读取一行,给定size表示最多读取指定的字符(字节)。
- 返回值: 返回读取到的内容
readlines([sizeint])
功能: 读取文件中的每一行作为列表中的一项
参数: 如果没有给定size参数(默认值为-1)或者size值为负,文件将被读取直至末尾,给定size表示读取到size字符所在行为止。
返回值: 返回读取到的内容列表
文件对象本身也是一个可迭代对象,在for循环中可以迭代文件的每一行。
1 | for line in f: |
(3)写入文件
- write(string)
- 功能: 把文本数据或二进制数据块的字符串写入到文件中去
- 参数:要写入的内容
- 如果需要换行要自己在写入内容中添加\n
- writelines(str_list)
- 功能:接受一个字符串列表作为参数,将它们写入文件。
- 参数: 要写入的内容列表
(4)关闭文件
打开一个文件后我们就可以通过文件对象对文件进行操作了,当操作结束后使用close()关闭这个对象可以防止一些误操作,也可以节省资源。
file_object.close()
(5)with操作
Python中with语句使用于对资源进行访问的场合,保证不管处理过程中是否发生错误或者异常都会
执行规定的”清理“操作,释放被访问的资源,比如有文件读写后自动关闭、线程中锁自动获取和释放。
1 | with context_expression [as target(s)]: |
- 通过with方法可以不用close(),因为with生成的对象在语句块结束后会自动处理,所以也就不需要close了,但是这个文件对象只能在with语句块内使用。
1 | with open('file','r+') as f: |
15.2 其他操作
(1)刷新缓冲区
- 缓冲:系统自动的在内存中为每一个正在使用的文件开辟一个缓冲区,从内存向磁盘输出数据必须先送到内存缓冲区,再由缓冲区送到磁盘中去。从磁盘中读数据,则一次从磁盘文件将一批数据读入到内存缓冲区中,然后再从缓冲区将数据送到程序的数据区。
刷新缓冲区条件:
缓冲区被写满
程序执行结束或者文件对象被关闭
行缓冲遇到换行
程序中调用flush()函数
- flush()
该函数调用后会进行一次磁盘交互,将缓冲区中的内容写入到磁盘。
- flush()
(2)文件偏移量
定义:打开一个文件进行操作时系统会自动生成一个记录,记录中描述了我们对文件的一系列操作。其中包括每次操作到的文件位置。文件的读写操作都是从这个位置开始进行的。
基本操作
tell()
- 功能:获取文件偏移量大小
seek(offset[,whence])
- 功能:移动文件偏移量位置
- 参数:
- offset 代表相对于某个位置移动的字节数。负数表示向前移动,正数表示向后移动。
- whence是基准位置的默认值为 0,代表从文件开头算起,1代表从当前位置算起,2 代表从文件末尾算起。
- 必须以二进制方式打开文件时基准位置才能是1或者2
(3)文件描述符
定义:系统中每一个IO操作都会分配一个整数作为编号,该整数即这个IO操作的文件描述符。
获取文件描述符
- fileno()
通过IO对象获取对应的文件描述符
- fileno()
15.3 文件管理函数
获取文件大小
os.path.getsize(file)
查看文件列表
os.listdir(dir)
查看文件是否存在
os.path.exists(file)
判断文件类型
os.path.isfile(file)
删除文件
os.remove(file)
16. 网络编程
计算机网络功能主要包括实现资源共享,实现数据信息的快速传递。
16.1 网络编程基础
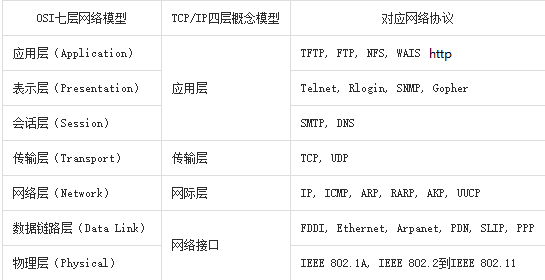
(1)OSI七层模型
制定组织: ISO(国际标准化组织)
作用:使网络通信工作流程标准化
应用层 : 提供用户服务,具体功能由应用程序实现
表示层 : 数据的压缩优化加密
会话层 : 建立用户级的连接,选择适当的传输服务
传输层 : 提供传输服务
网络层 : 路由选择,网络互联
链路层 : 进行数据交换,控制具体数据的发送
物理层 : 提供数据传输的硬件保证,网卡接口,传输介质
优点
- 建立了统一的工作流程
- 分部清晰,各司其职,每个步骤分工明确
- 降低了各个模块之间的耦合度,便于开发
(2)四层模型(TCP/IP模型)
背景 : 实际工作中工程师无法完全按照七层模型要求操作,逐渐演化为更符合实际情况的四层
1> 数据传输过程
- 发送端由应用程序发送消息,逐层添加首部信息,最终在物理层发送消息包。
- 发送的消息经过多个节点(交换机,路由器)传输,最终到达目标主机。
- 目标主机由物理层逐层解析首部消息包,最终到应用程序呈现消息。
2> 网络协议
在网络数据传输中,都遵循的规定,包括建立什么样的数据结构,什么样的特殊标志等。
3> 网络基础概念
- IP地址
功能:确定一台主机的网络路由位置
查看本机网络地址命令: ifconfig
结构
IPv4 点分十进制表示 172.40.91.185 每部分取值范围0–255
IPv6 128位 扩大了地址范围
- 域名
定义: 给网络服务器地址起的名字
作用: 方便记忆,表达一定的含义
ping [ip] : 测试和某个主机是否联通
- 端口号(port)
作用:端口是网络地址的一部分,用于区分主机上不同的网络应用程序。
特点:一个系统中的应用监听端口不能重复
取值范围: 1 – 65535
1–1023 系统应用或者大众程序监听端口
1024–65535 自用端口
(3)传输层服务
1> 基于TCP协议的数据传输
- 传输特征 : 提供了可靠的数据传输,可靠性指数据传输过程中无丢失,无失序,无差错,无重复。
- 实现手段 : 在通信前需要建立数据连接,通信结束要正常断开连接。
- 适用情况 : 对数据传输准确性有明确要求,传数文件较大,需要确保可靠性的情况。比如:网页获取,文件下载,邮件收发。
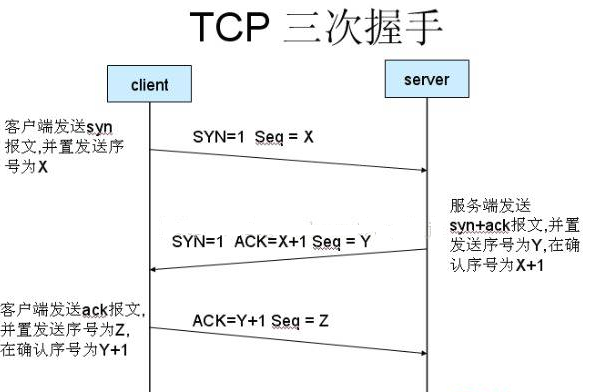
三次握手(建立连接)
客户端向服务器发送消息报文请求连接
服务器收到请求后,回复报文确定可以连接
客户端收到回复,发送最终报文连接建立
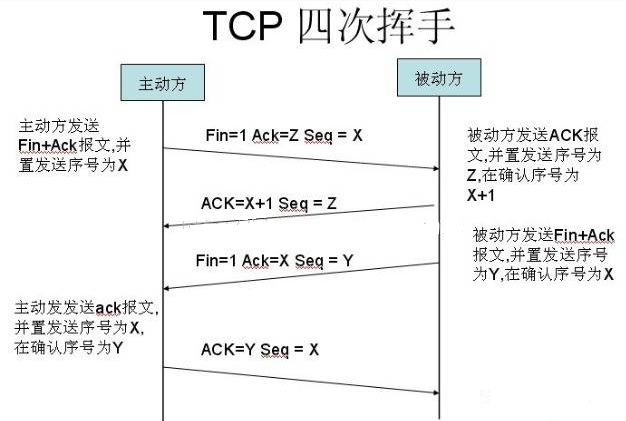
四次挥手(断开连接)
主动方发送报文请求断开连接
被动方收到请求后,立即回复,表示准备断开
被动方准备就绪,再次发送报文表示可以断开
主动方收到确定,发送最终报文完成断开
2 > 基于UDP协议的数据传输
- 传输特点 : 不保证传输的可靠性,传输过程没有连接和断开,数据收发自由随意。
- 适用情况 : 网络较差,对传输可靠性要求不高。比如:网络视频,群聊,广播
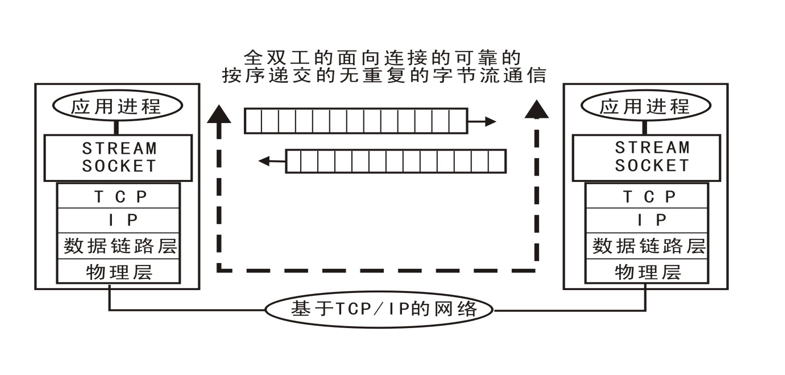
16.2 socket套接字编程
(1)套接字介绍
套接字 : 实现网络编程进行数据传输的一种技术手段
Python实现套接字编程:import socket
套接字分类
- 流式套接字(SOCK_STREAM): 以字节流方式传输数据,实现TCP网络传输方案。(面向连接–tcp协议–可靠的–流式套接字)
- 数据报套接字(SOCK_DGRAM): 以数据报形式传输数据,实现UDP网络传输方案。(无连接–udp协议–不可靠–数据报套接字)
(2)tcp套接字编程
1> 服务端流程
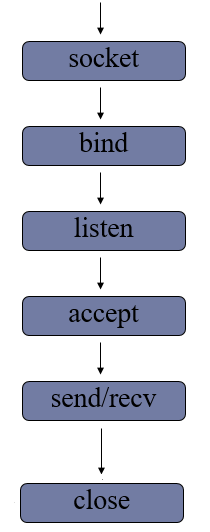
- 创建套接字
1 | sockfd=socket.socket(socket_family=AF_INET,socket_type=SOCK_STREAM,proto=0) |
- 绑定地址
本地地址 : ‘localhost’ , ‘127.0.0.1’
网络地址 : ‘172.40.91.185’
自动获取地址: ‘0.0.0.0’
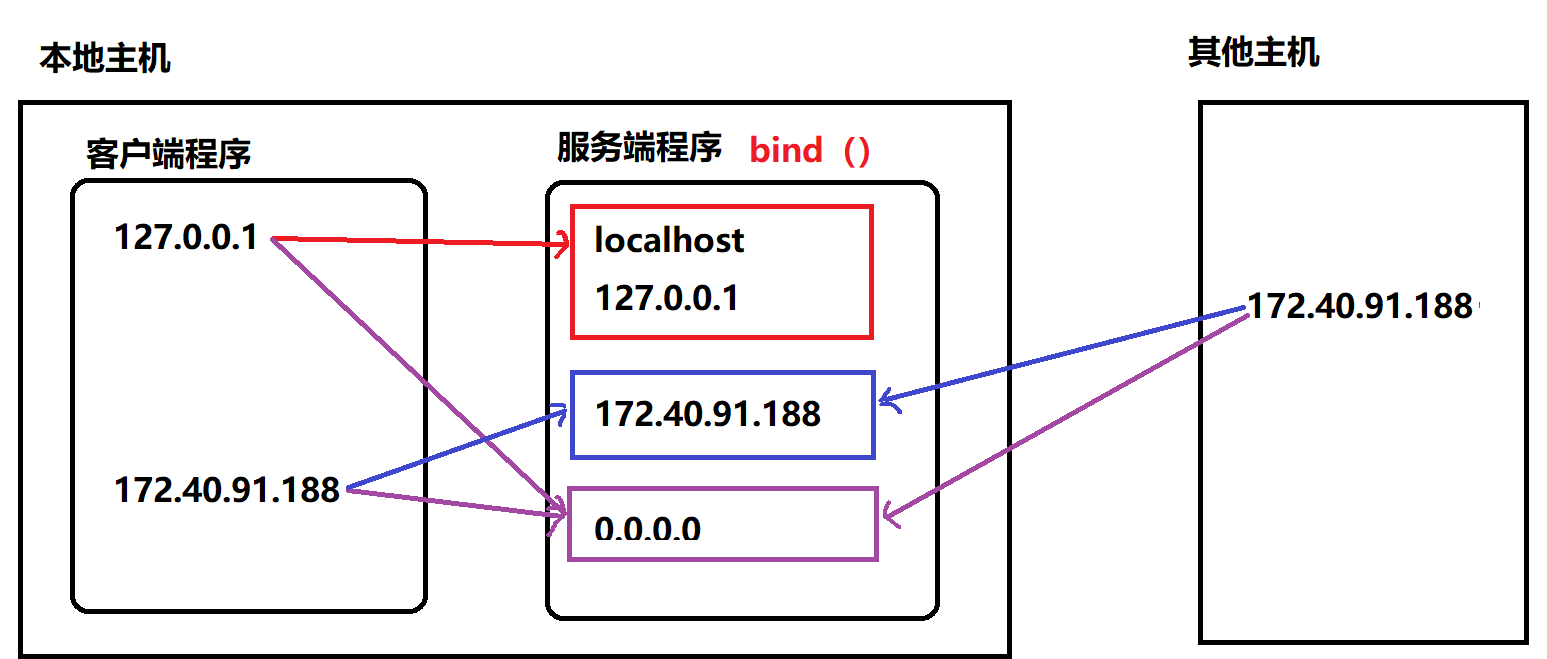
1 | sockfd.bind(addr) |
- 设置监听
1 | sockfd.listen(n) |
- 等待处理客户端连接请求
1 | connfd,addr = sockfd.accept() |
- 消息收发
1 | data = connfd.recv(buffersize) |
- 关闭套接字
1 | sockfd.close() |
2> 客户端流程
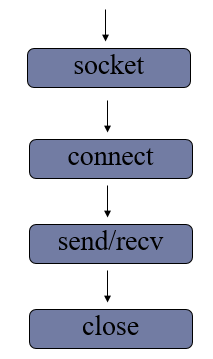
- 创建套接字
注意:只有相同类型的套接字才能进行通信
- 请求连接
1 | sockfd.connect(server_addr) |
- 收发消息
注意: 防止两端都阻塞,recv send要配合
- 关闭套接字
3> tcp 套接字数据传输特点
tcp连接中当一端退出,另一端如果阻塞在recv,此时recv会立即返回一个空字串。
tcp连接中如果一端已经不存在,仍然试图通过send发送则会产生BrokenPipeError
一个监听套接字可以同时连接多个客户端,也能够重复被连接
4> 网络收发缓冲区
- 网络缓冲区有效的协调了消息的收发速度
- send和recv实际是向缓冲区发送接收消息,当缓冲区不为空recv就不会阻塞。
5> tcp粘包
原因:tcp以字节流方式传输,没有消息边界。多次发送的消息被一次接收,此时就会形成粘包。
影响:如果每次发送内容是一个独立的含义,需要接收端独立解析此时粘包会有影响。
处理方法
- 人为的添加消息边界
- 控制发送速度
(3)UDP套接字编程
1> 服务端流程
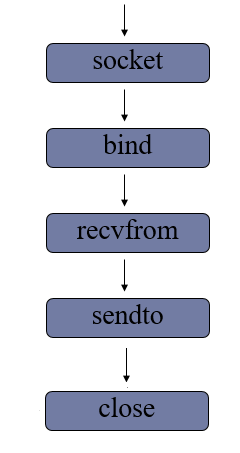
- 创建数据报套接字
1 | sockfd = socket(AF_INET,SOCK_DGRAM) |
- 绑定地址
1 | sockfd.bind(addr) |
- 消息收发
1 | data,addr = sockfd.recvfrom(buffersize) |
- 关闭套接字
1 | sockfd.close() |
2> 客户端流程
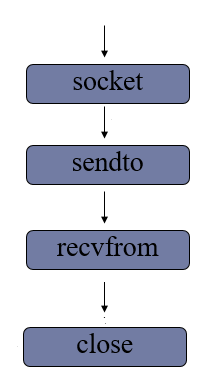
- 创建套接字
- 收发消息
- 关闭套接字
总结 :tcp套接字和udp套接字编程区别
- 流式套接字是以字节流方式传输数据,数据报套接字以数据报形式传输
- tcp套接字会有粘包,udp套接字有消息边界不会粘包
- tcp套接字保证消息的完整性,udp套接字则不能
- tcp套接字依赖listen accept建立连接才能收发消息,udp套接字则不需要
- tcp套接字使用send,recv收发消息,udp套接字使用sendto,recvfrom
(4)socket套接字属性
sockfd.type 套接字类型
sockfd.family 套接字地址类型
sockfd.getsockname() 获取套接字绑定地址
- sockfd.fileno() 获取套接字的文件描述符
- sockfd.getpeername() 获取连接套接字客户端地址
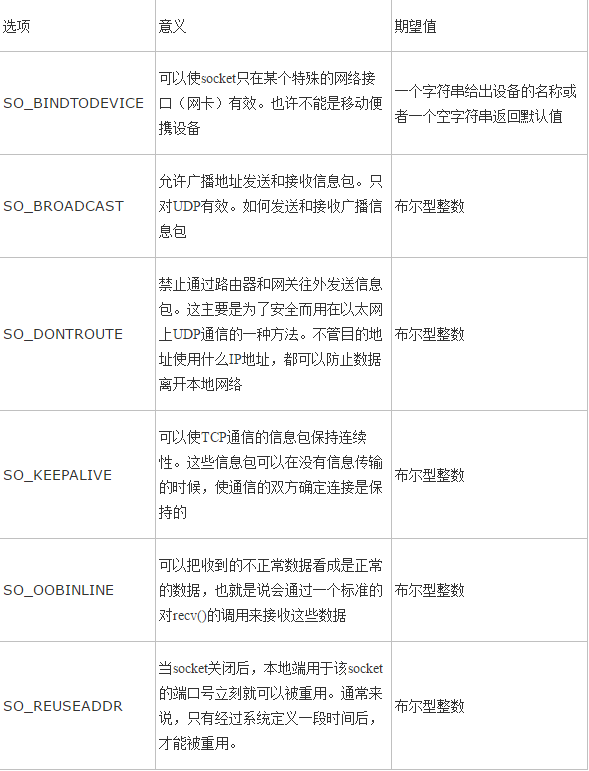
- sockfd.setsockopt(level,option,value)
- 功能:设置套接字选项
- 参数: level 选项类别 SOL_SOCKET
option 具体选项内容 value 选项值
16.3 struct模块进行数据打包
- 原理: 将一组简单数据进行打包,转换为bytes格式发送。或者将一组bytes格式数据,进行解析。
- 接口使用
1 | Struct(fmt) |
说明: 可以使用struct模块直接调用pack unpack。此时这两函数第一个参数传入fmt。其他用法功能相同
16.4 HTTP传输
(1)HTTP协议 (超文本传输协议)
用途 : 网页获取,数据的传输
特点
- 应用层协议,传输层使用tcp传输
- 简单,灵活,很多语言都有HTTP专门接口
- 无状态,协议不记录传输内容
- http1.1 支持持久连接,丰富了请求类型
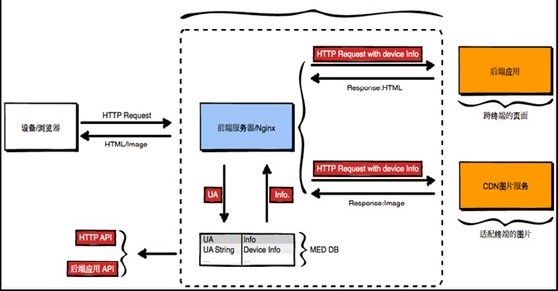
- 网页请求过程
1.客户端(浏览器)通过tcp传输,发送http请求给服务端
2.服务端接收到http请求后进行解析
3.服务端处理请求内容,组织响应内容
4.服务端将响应内容以http响应格式发送给浏览器
5.浏览器接收到响应内容,解析展示
(2)HTTP请求(request)
- 请求行 : 具体的请求类别和请求内容
1 | GET / HTTP/1.1 |
1 | 请求类别:每个请求类别表示要做不同的事情 |
- 请求头:对请求的进一步解释和描述
1 | Accept-Encoding: gzip |
- 空行
- 请求体: 请求参数或者提交内容
(3)http响应(response)
- 响应格式:响应行,响应头,空行,响应体
- 响应行 : 反馈基本的响应情况
1 | HTTP/1.1 200 OK |
1 | 响应码 : |
- 响应头:对响应内容的描述
1 | Content-Type: text/html |
- 响应体:响应的主体内容信息
17. 并发编程
17.1 多任务编程
- 意义: 充分利用计算机CPU的多核资源,同时处理多个应用程序任务,以此提高程序的运行效率。
- 实现方案 :多进程 , 多线程
17.2 进程(process)
(1)进程理论基础
系统中如何产生一个进程
【1】 用户空间通过调用程序接口或者命令发起请求
【2】 操作系统接收用户请求,开始创建进程
【3】 操作系统调配计算机资源,确定进程状态等
【4】 操作系统将创建的进程提供给用户使用
cpu时间片:如果一个进程占有cpu内核则称这个进程在cpu时间片上。
PCB(进程控制块):在内存中开辟的一块空间,用于存放进程的基本信息,也用于系统查找识别进程。
进程ID(PID): 系统为每个进程分配的一个大于0的整数,作为进程ID。每个进程ID不重复。
Linux查看进程ID : ps -aux
父子进程 : 系统中每一个进程(除了系统初始化进程)都有唯一的父进程,可以有0个或多个子进程。父子进程关系便于进程管理。
查看进程树: pstree
进程状态
- 三态
就绪态 : 进程具备执行条件,等待分配cpu资源
运行态 : 进程占有cpu时间片正在运行
等待态 : 进程暂时停止运行,让出cpu
- 三态
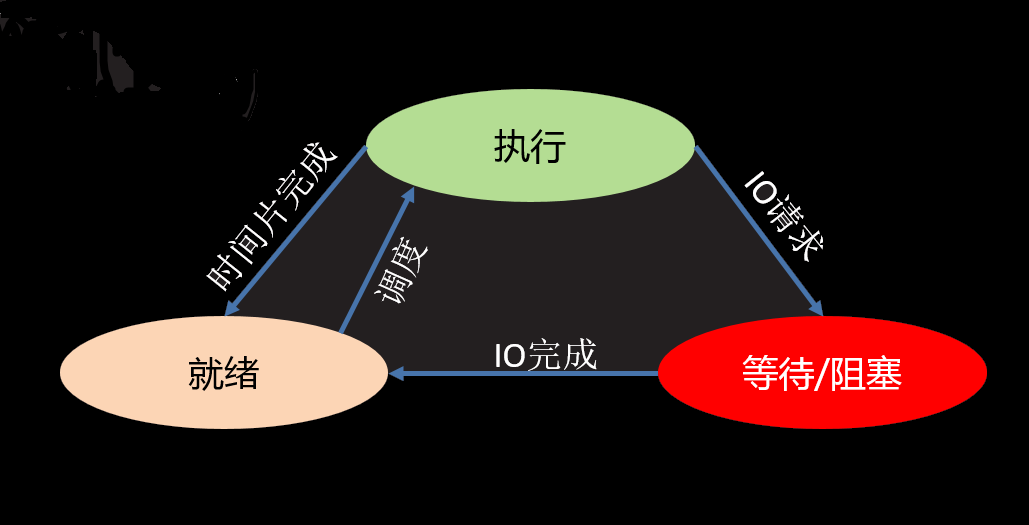
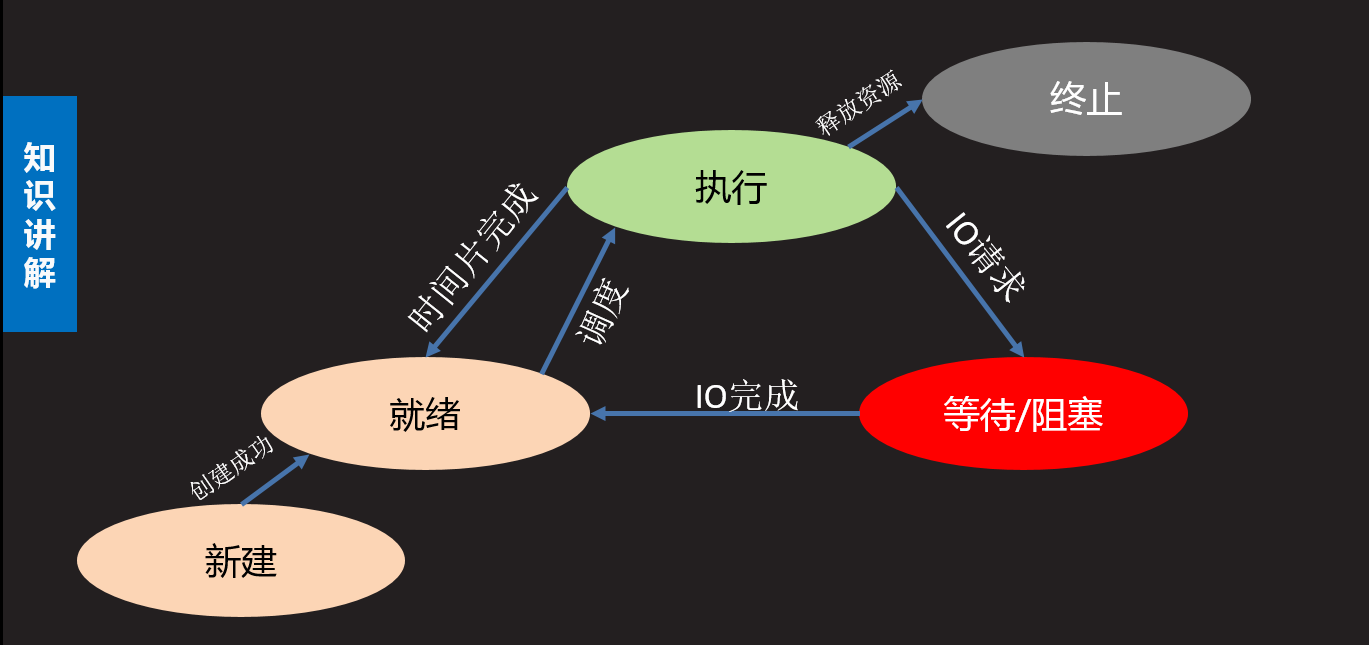
- 五态 (在三态基础上增加新建和终止)
新建 : 创建一个进程,获取资源的过程
终止 : 进程结束,释放资源的过程
- 状态查看命令 : ps -aux –> STAT列
S 等待态 R 执行态 Z 僵尸 \+ 前台进程 l 有多线程的
- 进程的运行特征
【1】 多进程可以更充分使用计算机多核资源
【2】 进程之间的运行互不影响,各自独立
【3】 每个进程拥有独立的空间,各自使用自己空间资源
17.3 基于fork的多进程编程
(1)fork使用
pid = os.fork()
功能: 创建新的进程
返回值:整数,如果创建进程失败返回一个负数,如果成功则在原有进程中返回新进程的PID,在新进程中返回0
注意
- 子进程会复制父进程全部内存空间,从fork下一句开始执行。
- 父子进程各自独立运行,运行顺序不一定。
- 利用父子进程fork返回值的区别,配合if结构让父子进程执行不同的内容几乎是固定搭配。
- 父子进程有各自特有特征比如PID PCB 命令集等。
- 父进程fork之前开辟的空间子进程同样拥有,父子进程对各自空间的操作不会相互影响。
(2)进程相关函数
os.getpid()
功能: 获取一个进程的PID值
返回值: 返回当前进程的PID
os.getppid()
功能: 获取父进程的PID号
返回值: 返回父进程PID
os._exit(status)
功能: 结束一个进程
参数:进程的终止状态
sys.exit([status])
功能:退出进程
参数:整数 表示退出状态
字符串 表示退出时打印内容
(3)孤儿和僵尸
- 孤儿进程 : 父进程先于子进程退出,此时子进程成为孤儿进程。
特点: 孤儿进程会被系统进程收养,此时系统进程就会成为孤儿进程新的父进程,孤儿进程退出该进程会自动处理。
- 僵尸进程 : 子进程先于父进程退出,父进程又没有处理子进程的退出状态,此时子进程就会称为僵尸进程。
特点: 僵尸进程虽然结束,但是会存留部分PCB在内存中,大量的僵尸进程会浪费系统的内存资源。
- 如何避免僵尸进程产生
- 使用wait函数处理子进程退出
1 | pid,status = os.wait() |
创建二级子进程处理僵尸
【1】 父进程创建子进程,等待回收子进程
【2】 子进程创建二级子进程然后退出
【3】 二级子进程称为孤儿,和原来父进程一同执行事件
通过信号处理子进程退出
原理: 子进程退出时会发送信号给父进程,如果父进程忽略子进程信号,则系统就会自动处理子进程退出。
方法: 使用signal模块在父进程创建子进程前写如下语句 :
1
2import signal
signal.signal(signal.SIGCHLD,signal.SIG_IGN)特点 : 非阻塞,不会影响父进程运行。可以处理所有子进程退出
(4)群聊聊天室
功能 : 类似qq群功能
【1】 有人进入聊天室需要输入姓名,姓名不能重复
【2】 有人进入聊天室时,其他人会收到通知:xxx 进入了聊天室
【3】 一个人发消息,其他人会收到:xxx : xxxxxxxxxxx
【4】 有人退出聊天室,则其他人也会收到通知:xxx退出了聊天室
【5】 扩展功能:服务器可以向所有用户发送公告:管理员消息: xxxxxxxxx
17.4 multiprocessing 模块创建进程
(1)进程创建方法
流程特点
【1】 将需要子进程执行的事件封装为函数
【2】 通过模块的Process类创建进程对象,关联函数
【3】 可以通过进程对象设置进程信息及属性
【4】 通过进程对象调用start启动进程
【5】 通过进程对象调用join回收进程基本接口使用
1 | Process() |
1 | p.start() |
注意:启动进程此时target绑定函数开始执行,该函数作为子进程执行内容,此时进程真正被创建
1 | p.join([timeout]) |
注意
- 使用multiprocessing创建进程同样是子进程复制父进程空间代码段,父子进程运行互不影响。
- 子进程只运行target绑定的函数部分,其余内容均是父进程执行内容。
- multiprocessing中父进程往往只用来创建子进程、回收子进程,具体事件由子进程完成。
- multiprocessing创建的子进程中无法使用标准输入
p.name 进程名称
p.pid 对应子进程的PID号
p.is_alive() 查看子进程是否在生命周期
p.daemon 设置父子进程的退出关系
- 如果设置为True则子进程会随父进程的退出而结束
- 要求必须在start()前设置
- 如果daemon设置成True 通常就不会使用 join()
(2)自定义进程类
创建步骤
【1】 继承Process类
【2】 重写__init__方法添加自己的属性,使用super()加载父类属性
【3】 重写run()方法使用方法
【1】 实例化对象
【2】 调用start自动执行run方法
【3】 调用join回收进程
(3)进程池实现
创建一定数量的进程来处理事件,事件处理完进程不退出而是继续处理其他事件,直到所有事件全都处理完毕统一销毁。增加进程的重复利用,降低资源消耗。
【1】 创建进程池对象,放入适当的进程
1 | from multiprocessing import Pool |
【2】 将事件加入进程池队列执行
1 | pool.apply_async(func,args,kwds) |
【3】 关闭进程池
1 | pool.close() |
【4】 回收进程池中进程
1 | pool.join() |
17.5 进程间通信(IPC)
- 必要性: 进程间空间独立,资源不共享,此时在需要进程间数据传输时就需要特定的手段进行数据通信。
- 常用进程间通信方法
管道 消息队列 共享内存 信号 信号量 套接字
(1)管道通信(Pipe)
在内存中开辟管道空间,生成管道操作对象,多个进程使用同一个管道对象进行读写即可实现通信
1 | from multiprocessing import Pipe |
(2)消息队列
- 通信原理
在内存中建立队列模型,进程通过队列将消息存入,或者从队列取出完成进程间通信。
- 实现方法
1 | from multiprocessing import Queue |
(3)共享内存
1 | from multiprocessing import Value,Array |
(4)信号量(信号灯集)
- 通信原理
给定一个数量对多个进程可见。多个进程都可以操作该数量增减,并根据数量值决定自己的行为。
- 实现方法
1 | from multiprocessing import Semaphore |
17.6 线程编程(Thread)
(1)线程基本概念
什么是线程
【1】 线程被称为轻量级的进程
【2】 线程也可以使用计算机多核资源,是多任务编程方式
【3】 线程是系统分配内核的最小单元
【4】 线程可以理解为进程的分支任务线程特征
【1】 一个进程中可以包含多个线程
【2】 线程也是一个运行行为,消耗计算机资源
【3】 一个进程中的所有线程共享这个进程的资源
【4】 多个线程之间的运行互不影响各自运行
【5】 线程的创建和销毁消耗资源远小于进程
【6】 各个线程也有自己的ID等特征
(2)threading模块创建线程
【1】 创建线程对象
1 | from threading import Thread |
【2】 启动线程
1 | t.start() |
【3】 回收线程
1 | t.join([timeout]) |
(3)线程对象属性
t.name 线程名称
t.setName() 设置线程名称
t.getName() 获取线程名称
t.is_alive() 查看线程是否在生命周期
t.daemon 设置主线程和分支线程的退出关系
t.setDaemon() 设置daemon属性值
t.isDaemon() 查看daemon属性值daemon为True时主线程退出分支线程也退出。要在start前设置,通常不和join一起使用。
(4)自定义线程类
创建步骤
【1】 继承Thread类
【2】 重写__init__方法添加自己的属性,使用super()加载父类属性
【3】 重写run()方法使用方法
【1】 实例化对象
【2】 调用start自动执行run方法
【3】 调用join回收线程
17.7 同步互斥
(1)线程间通信方法
- 通信方法
线程间使用全局变量进行通信
- 共享资源争夺
共享资源:多个进程或者线程都可以操作的资源称为共享资源。对共享资源的操作代码段称为临界区。
影响 : 对共享资源的无序操作可能会带来数据的混乱,或者操作错误。此时往往需要同步互斥机制协调操作顺序。
- 同步互斥机制
同步 : 同步是一种协作关系,为完成操作,多进程或者线程间形成一种协调,按照必要的步骤有序执行操作。
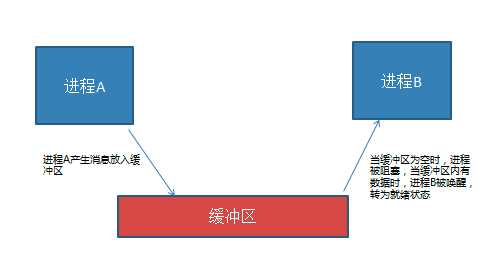
互斥 : 互斥是一种制约关系,当一个进程或者线程占有资源时会进行加锁处理,此时其他进程线程就无法操作该资源,直到解锁后才能操作。
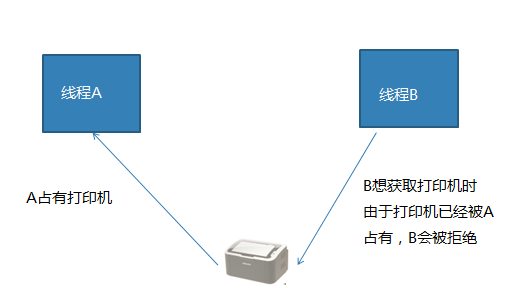
(2)线程同步互斥方法
1> 线程Event
1 | from threading import Event |
2> 线程锁 Lock
1 | from threading import Lock |
(3)死锁及其处理
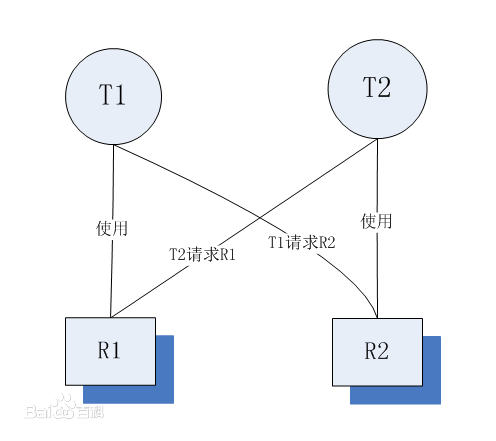
死锁是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁。
死锁发生的必要条件
- 互斥条件:指线程对所分配到的资源进行排它性使用,即在一段时间内某资源只由一个进程占用。如果此时还有其它进程请求资源,则请求者只能等待,直至占有资源的进程用毕释放。
- 请求和保持条件:指线程已经保持至少一个资源,但又提出了新的资源请求,而该资源已被其它进程占有,此时请求线程阻塞,但又对自己已获得的其它资源保持不放。
- 不剥夺条件:指线程已获得的资源,在未使用完之前,不能被剥夺,只能在使用完时由自己释放,通常CPU内存资源是可以被系统强行调配剥夺的。
- 环路等待条件:指在发生死锁时,必然存在一个线程——资源的环形链,即进程集合{T0,T1,T2,···,Tn}中的T0正在等待一个T1占用的资源;T1正在等待T2占用的资源,……,Tn正在等待已被T0占用的资源。
死锁的产生原因
简单来说造成死锁的原因可以概括成三句话:
- 当前线程拥有其他线程需要的资源
- 当前线程等待其他线程已拥有的资源
- 都不放弃自己拥有的资源
如何避免死锁
死锁是我们非常不愿意看到的一种现象,我们要尽可能避免死锁的情况发生。通过设置某些限制条件,去破坏产生死锁的四个必要条件中的一个或者几个,来预防发生死锁。预防死锁是一种较易实现的方法。但是由于所施加的限制条件往往太严格,可能会导致系统资源利用率。
17.8 python线程GIL
- python线程的GIL问题 (全局解释器锁)
什么是GIL :由于python解释器设计中加入了解释器锁,导致python解释器同一时刻只能解释执行一个线程,大大降低了线程的执行效率。
导致后果: 因为遇到阻塞时线程会主动让出解释器,去解释其他线程。所以python多线程在执行多阻塞高延迟IO时可以提升程序效率,其他情况并不能对效率有所提升。
GIL问题建议
- 尽量使用进程完成无阻塞的并发行为
- 不使用c作为解释器 (Java C#)
- 结论 : 在无阻塞状态下,多线程程序和单线程程序执行效率几乎差不多,甚至还不如单线程效率。但是多进程运行相同内容却可以有明显的效率提升。
17.9 进程线程的区别联系
(1)区别联系
- 两者都是多任务编程方式,都能使用计算机多核资源
- 进程的创建删除消耗的计算机资源比线程多
- 进程空间独立,数据互不干扰,有专门通信方法;线程使用全局变量通信
- 一个进程可以有多个分支线程,两者有包含关系
- 多个线程共享进程资源,在共享资源操作时往往需要同步互斥处理
- 进程线程在系统中都有自己的特有属性标志,如ID,代码段,命令集等。
(2)使用场景
任务场景:如果是相对独立的任务模块,可能使用多进程,如果是多个分支共同形成一个整体任务可能用多线程
项目结构:多种编程语言实现不同任务模块,可能是多进程,或者前后端分离应该各自为一个进程。
难易程度:通信难度,数据处理的复杂度来判断用进程间通信还是同步互斥方法。
(3)要求
- 对进程线程怎么理解/说说进程线程的差异
- 进程间通信知道哪些,有什么特点
- 什么是同步互斥,你什么情况下使用,怎么用
- 给一个情形,说说用进程还是线程,为什么
- 问一些概念,僵尸进程的处理,GIL问题,进程状态
17.10 并发网络通信模型
(1)常见网络模型
- 循环服务器模型 :循环接收客户端请求,处理请求。同一时刻只能处理一个请求,处理完毕后再处理下一个。
优点:实现简单,占用资源少
缺点:无法同时处理多个客户端请求
适用情况:处理的任务可以很快完成,客户端无需长期占用服务端程序。udp比tcp更适合循环。
- 多进程/线程网络并发模型:每当一个客户端连接服务器,就创建一个新的进程/线程为该客户端服务,客户端退出时再销毁该进程/线程。
优点:能同时满足多个客户端长期占有服务端需求,可以处理各种请求。
缺点: 资源消耗较大
适用情况:客户端同时连接量较少,需要处理行为较复杂情况。
IO并发模型:利用IO多路复用,异步IO等技术,同时处理多个客户端IO请求。
优点 : 资源消耗少,能同时高效处理多个IO行为
缺点 : 只能处理并发产生的IO事件,无法处理cpu计算适用情况:HTTP请求,网络传输等都是IO行为。
(2)基于fork的多进程网络并发模型
实现步骤
- 创建监听套接字
- 等待接收客户端请求
- 客户端连接创建新的进程处理客户端请求
- 原进程继续等待其他客户端连接
- 如果客户端退出,则销毁对应的进程
(3)基于threading的多线程网络并发
实现步骤
- 创建监听套接字
- 循环接收客户端连接请求
- 当有新的客户端连接创建线程处理客户端请求
- 主线程继续等待其他客户端连接
- 当客户端退出,则对应分支线程退出
(4)ftp 文件服务器
- 功能
【1】 分为服务端和客户端,要求可以有多个客户端同时操作。
【2】 客户端可以查看服务器文件库中有什么文件。
【3】 客户端可以从文件库中下载文件到本地。
【4】 客户端可以上传一个本地文件到文件库。
【5】 使用print在客户端打印命令输入提示,引导操作
17.11 IO并发
(1)IO 分类
IO分类:阻塞IO ,非阻塞IO,IO多路复用,异步IO等
1> 阻塞IO
定义:在执行IO操作时如果执行条件不满足则阻塞。阻塞IO是IO的默认形态。
效率:阻塞IO是效率很低的一种IO。但是由于逻辑简单所以是默认IO行为。
阻塞情况:
因为某种执行条件没有满足造成的函数阻塞
e.g. accept input recv处理IO的时间较长产生的阻塞状态
e.g. 网络传输,大文件读写
2> 非阻塞IO
- 定义 :通过修改IO属性行为,使原本阻塞的IO变为非阻塞的状态。
设置套接字为非阻塞IO
sockfd.setblocking(bool)
功能:设置套接字为非阻塞IO
参数:默认为True,表示套接字IO阻塞;设置为False则套接字IO变为非阻塞超时检测 :设置一个最长阻塞时间,超过该时间后则不再阻塞等待。
sockfd.settimeout(sec)
功能:设置套接字的超时时间
参数:设置的时间
(2)IO多路复用
定义
同时监控多个IO事件,当哪个IO事件准备就绪就执行哪个IO事件。以此形成可以同时处理多个IO的行为,避免一个IO阻塞造成其他IO均无法执行,提高了IO执行效率。
具体方案
select方法 : windows linux unix
poll方法: linux unix
epoll方法: linux
1> select 方法
1 | rs, ws, xs=select(rlist, wlist, xlist[, timeout]) |
select 实现tcp服务
【1】 将关注的IO放入对应的监控类别列表
【2】通过select函数进行监控
【3】遍历select返回值列表,确定就绪IO事件
【4】处理发生的IO事件
注意
wlist中如果存在IO事件,则select立即返回给ws
处理IO过程中不要出现死循环占有服务端的情况
IO多路复用消耗资源较少,效率较高
2> poll方法
代码实现: day12/poll_server.py
1 | p = select.poll() |
1 | p.register(fd,event) |
1 | events = p.poll() |
poll_server 步骤
【1】 创建套接字
【2】 将套接字register
【3】 创建查找字典,并维护
【4】 循环监控IO发生
【5】 处理发生的IO
3> epoll方法
使用方法 : 基本与poll相同
- 生成对象改为 epoll()
- 将所有事件类型改为EPOLL类型
epoll特点
- epoll 效率比select poll要高
- epoll 监控IO数量比select要多
- epoll 的触发方式比poll要多 (EPOLLET边缘触发)
(3)协程技术
1> 基础概念
定义:纤程,微线程。是允许在不同入口点不同位置暂停或开始的计算机程序,简单来说,协程就是可以暂停执行的函数。
协程原理 : 记录一个函数的上下文,协程调度切换时会将记录的上下文保存,在切换回来时进行调取,恢复原有的执行内容,以便从上一次执行位置继续执行。
协程优缺点
优点
- 协程完成多任务占用计算资源很少
- 由于协程的多任务切换在应用层完成,因此切换开销少
- 协程为单线程程序,无需进行共享资源同步互斥处理
缺点
协程的本质是一个单线程,无法利用计算机多核资源
python3.5以后,使用标准库asyncio和async/await 语法来编写并发代码。asyncio库通过对异步IO行为的支持完成python的协程。虽然官方说asyncio是未来的开发方向,但是由于其生态不够丰富,大量的客户端不支持awaitable需要自己去封装,所以在使用上存在缺陷。更多时候只能使用已有的异步库(asyncio等),功能有限
2> 第三方协程模块
- greenlet模块
安装 : sudo pip3 install greenlet
函数
1 | greenlet.greenlet(func) |
- gevent模块
安装:sudo pip3 install gevent
函数
1 | gevent.spawn(func,argv) |
- monkey脚本
作用:在gevent协程中,协程只有遇到gevent指定类型的阻塞才能跳转到其他协程,因此,我们希望将普通的IO阻塞行为转换为可以触发gevent协程跳转的阻塞,以提高执行效率。
转换方法:gevent 提供了一个脚本程序monkey,可以修改底层解释IO阻塞的行为,将很多普通阻塞转换为gevent阻塞。
使用方法
【1】 导入monkey
from gevent import monkey
【2】 运行相应的脚本,例如转换socket中所有阻塞
monkey.patch_socket()
【3】 如果将所有可转换的IO阻塞全部转换则运行all
monkey.patch_all()
【4】 注意:脚本运行函数需要在对应模块导入前执行
 微信
微信 支付宝
支付宝

